Architecture de l'ETL
10 Mars 2023 (mis à jour le 24 Juillet 2024)
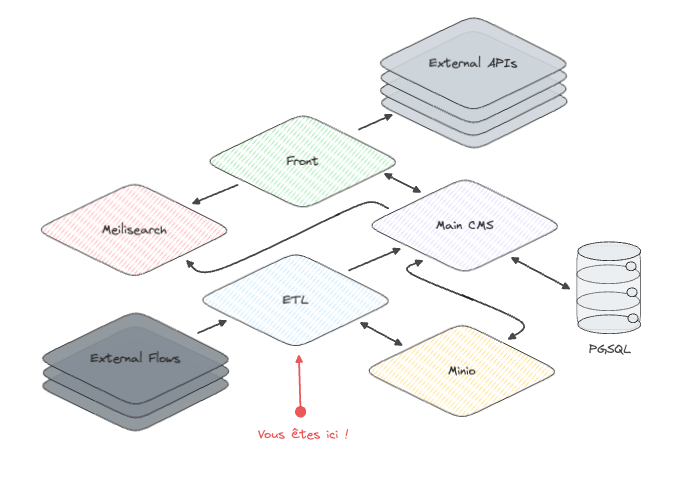
Architecture globale
Introduction
Ce projet a été réalisé en suivant au mieux les principes du Domain-Driven Design.
C'est pourquoi nous avons identifié des contextes métier indépendants les uns des autres comme représentés ci-dessous :
Au 10/03/2023 :
Point d'entrée
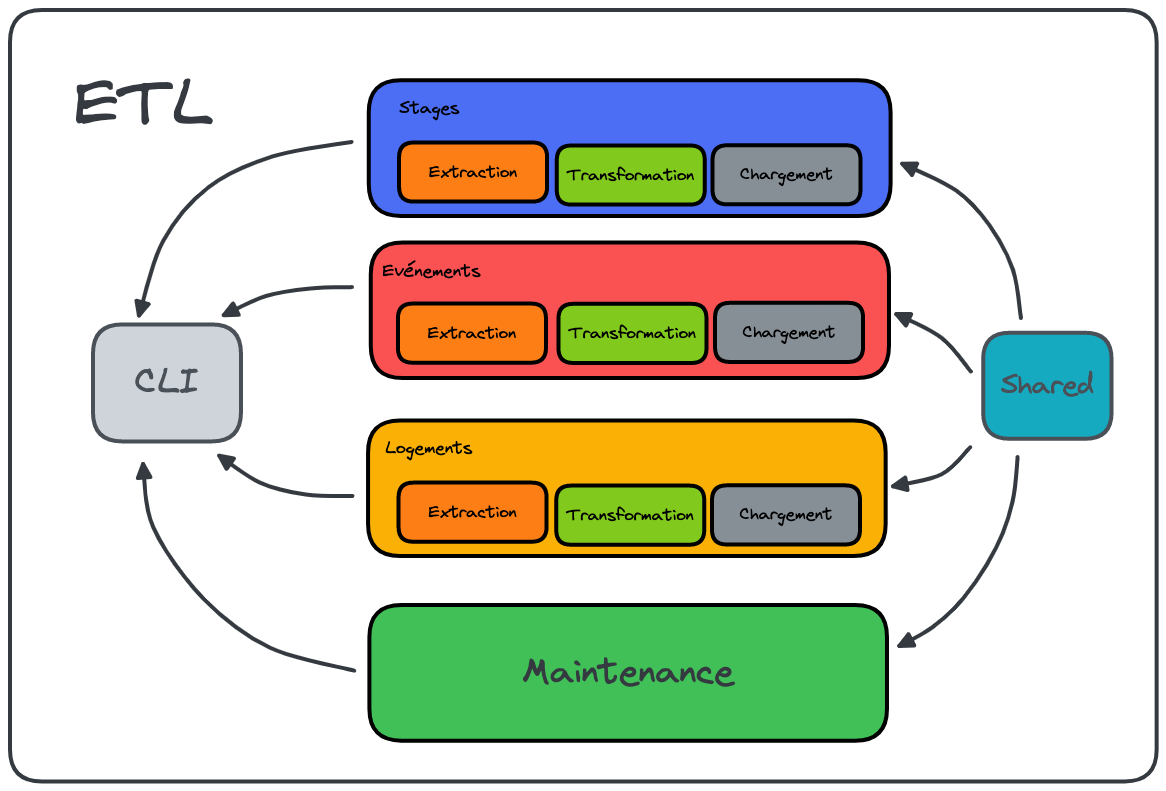
Le point d'entrée de l'application est ici la Command Line Interface (CLI). En effet, l'ETL est aujourd'hui un produit "serverless" ou "Function as a Service" (FaaS). De ce fait, nous exécutons de simples fonctions à intervalles réguliers au travers de la CLI du projet.
Lancer une opération depuis la CLI demande quelques options nécessaires pour savoir quoi lancer :
$ npm run cli -- [extract|transform|load] [flowName]
Pour aller plus loin sur la commande shell ci-dessus :
npm run clinous donne accès à la CLI ;--nous permet d'ajouter des options supplémentaires à l'action précédente ;[extract|transform|load]nous permet de choisir quelle action est à réaliser ;[flowName]nous permet de choisir sur quel flux nous souhaitons réaliser notre action.
Modules
Comme nous le disions plus haut, nous avons découpé notre application par contexte métier. De ce fait, nous avons identifiés les 3 modules suivants :
evenementslogementsmaintenancestages
Cela se traduit dans le code par 3 modules distincts totalement isolés les uns des autres.
Sous-modules
De la même façon que pour les modules, nous avons identifié des sous-modules pour chaque module :
chargementextractiontransformation
Chaque sous-module suit les principes de l'Onion Architecture et ressemble à l'arborescence suivante :
sous-module
├─── application-service
├─── domain
│ ├── model
│ └── service
├─── infrastructure
└─── index.ts